

Creación de la solución de análisis predictivas de AppsFlyer



La introducción de insights predictivos en la pila de tecnología del desarrollador de aplicaciones promedio puede ofrecer a los clientes de AppsFlyer una ventaja competitiva sin precedentes, así como también mejorar muchos de los productos de AppsFlyer, desde la incrementalidad hasta la protección contra el fraude.
El primer paso para implementar tales insights se llevó a cabo a través de las predicciones del valor de vida útil (LTV) de la campaña.
La fórmula del valor de vida útil (LTV)
El valor de vida útil (LTV) de cada campaña se determina en las semanas siguientes a la instalación de una aplicación, donde las decisiones de UA solo se toman en el presente, dada la información actual: lo que significa que cada decisión, en cualquier momento, dará como resultado un nivel de incertidumbre en el LTV.
El administrador de UA promedio podría lanzar una campaña y esperar la cantidad de tiempo adecuada para que lleguen los datos de LTV de los usuarios iniciales antes de tomar decisiones de optimización. Este período de espera podría demorar hasta 30 días o más (en muchos casos), pero también podría reducirse a 10-15 días si se utilizan herramientas avanzadas de Business Intelligence y analíticas.
Nuestro objetivo era eliminar este período de espera, que definimos como el “período de incertidumbre”, en el que las campañas desperdiciarían dinero mientras esperaban los resultados. Para ello, nos propusimos el ambicioso objetivo de proporcionar insights predictivos sobre el LTV de los usuarios para el día 30, basados en las primeras 24 horas de engagement del usuario.
Pero, ¿cómo se puede aplicar una fórmula de LTV a la infinita variedad de cálculos de LTV que usan los clientes de AppsFlyer?
Después de realizar una investigación de mercado exhaustiva, nuestro equipo redujo las posibilidades a tres pilares principales que encapsulan los aspectos del LTV necesarios para la toma de decisiones en la actividad de adquisición de usuarios:
- Retención: medir cuánto tiempo se espera que un usuario use la aplicación.
- Engagement: analizar el nivel de engagement de un usuario con el entorno de la aplicación.
- Monetización: puntuar el potencial de generación de ingresos del usuario, a través de anuncios, compras y más.
Cada uno de los pilares anteriores se mide en diferentes escalas, por lo que para tenerlos todos en consideración o normalizarlos, todos tendrían que normalizarse. Para ello, decidimos aplicar un sistema de puntuación relativa que asociara cada pilar con una puntuación prevista única que oscilara entre 1 y 9.
Además, un factor clave sería considerar los costos de la campaña, ya que mediría el LTV relativo de un usuario frente al costo de adquirirlo. Aunque no se requiere ninguna predicción para el costo, porque es una cifra fija, aún requiere una puntuación para adaptarse al sistema de puntuación normalizado.
Creación de una solución alrededor de los activos existentes
Ahora era el momento de empezar a consultar los datos disponibles e identificar los puntos de datos adecuados que se pueden convertir en etiquetas y características de aprendizaje de máquina.
Entendimos que cualquier solución que construyéramos tendría que abarcar una solución multitenencia, es decir, una solución que se adaptara a la mayor cantidad posible de clientes de AppsFlyer; a pesar de las diferencias inherentes en la vertical, el uso y la popularidad de la aplicación, así como los diferentes modelos comerciales.
Inicialmente, nos enfocamos en puntos de datos que estaban ampliamente disponibles en todos los clientes de AppsFlyer. Factores clave como la recencia, la frecuencia de uso, las compras in-app y los ingresos por publicidad in-app fueron los componentes “obvios” con la lógica de monetización de cualquier aplicación.
Los eventos in-app de AppsFlyer son un excelente ejemplo de puntos de datos de este tipo, ya que se anima a todos los clientes a utilizarlos de una manera u otra en sus aplicaciones.
Con los eventos in-app, AppsFlyer siempre ha brindado flexibilidad a sus clientes, tanto en el tiempo (cuándo se debe enviar un evento/seguir qué acciones), como en el contenido, los nombres de eventos o cualquier otro parámetro que valga la pena reportar.
Por un lado, esto significa que los propietarios de aplicaciones pueden adaptar estos eventos in-app para que se ajusten a sus propias necesidades específicas, proporcionando insights valiosos que sean más relevantes para el ecosistema de su aplicación.
Por otro lado, significa que parte de esta información no se puede convertir en una característica o etiqueta de aprendizaje de máquina. Al menos no sin una capa de mediación que tendría que traducir la información que un evento in-app lleva a la categoría del componente de valor de vida útil (LTV) correspondiente.
Decidimos abordar este problema desde ambos extremos. El primero, construir un proceso que pueda inspeccionar datos históricos de eventos de los clientes y determinar la “jerarquía” probabilística de los eventos. Al mismo tiempo, recomendamos encarecidamente que nuestros clientes ofrezcan una asignación de eventos a las categorías correspondientes y la importancia de estos eventos a su lógica de LTV desde su perspectiva.
La combinación de estos métodos nos dio el insight para hacer uso de los datos históricos de los clientes y crear nuestros conjuntos de datos de capacitación de aprendizaje de máquina.
Validación del proceso
Una vez que pudimos validar con nuestros partners de diseño que los puntos de datos que elegimos eran óptimos para describir mejor el valor de vida útil (LTV) del usuario, pudimos proceder a la inspección de la distribución dentro de nuestros datos seleccionados. La distribución de características u objetivos dentro del conjunto de datos tiene una gran importancia para un aprendizaje de máquina preciso.
Trabajar con un conjunto de datos disperso, donde casi todos los “objetivos” se distribuyen alrededor del mismo punto, no va a producir grandes resultados. Por ejemplo, si un desarrollador de aplicaciones solo reporta el nivel de progreso en el que un usuario alcanza el nivel 500, pero en realidad el 99,9 % de todos los usuarios de la aplicación nunca alcanzarán ese nivel, terminaremos con una distribución de características/objetivos que no se pueden usar para nuestra predicción de engagement.
Este es un punto de decisión crucial en el proceso de onboarding de cualquier aplicación: si la aplicación no está haciendo un uso significativo de AppsFlyer (enviando eventos in-app, proporcionando información de compra y eventos de ingresos por publicidad, etc.), no podremos crear un modelo de predicción que sea confiable y lo suficientemente preciso. Este tipo de escenario requiere que el cliente aumente el uso de las capacidades de AppsFlyer antes del onboarding.
Después de garantizar que el proceso que creamos para transformar el raw data de los clientes en componentes de LTV que deseamos predecir funcione bien (para las aplicaciones elegibles), nos centramos en garantizar que el sistema de puntuación que deseamos usar fuera el adecuado. Esto significa garantizar que este sistema de puntuación describa con precisión los datos analizados (en términos de distribución y desviación estándar) y pueda ser más beneficioso para nuestros clientes por tomar decisiones de UA con claridad y confianza.
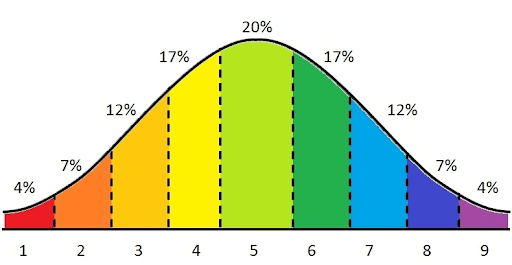
Elegimos implementar la puntuación de Stanine con puntuaciones en la escala 1-9.
Esta escala es conveniente tanto en sus diferencias de puntuación (no demasiado pequeñas para que la diferencia no sea insignificante y no demasiado grandes para reflejar las principales diferencias entre las campañas) como en su distribución estándar de dos, lo que permite calcular fácilmente el percentil de una campaña.
En algunos casos, cuando la distribución de datos no era “perfectamente normal” pero se parecía a la distribución normal, utilizamos transformaciones de Box Cox para redistribuir la población objetivo a una distribución “más normal”.
La naturaleza de serie temporal del LTV alentó nuestra hipótesis de que una solución basada en RNN probablemente podría producir los mejores resultados. Después de algunas pruebas e investigaciones, decidimos usar Tensorflow como el marco de aprendizaje de máquina y comenzamos a desarrollar nuestro algoritmo usando la API Keras.Sequential, y luego pasamos a la API funcional que permitió más flexibilidad; sin embargo, fue más complejo.
Valor de producción
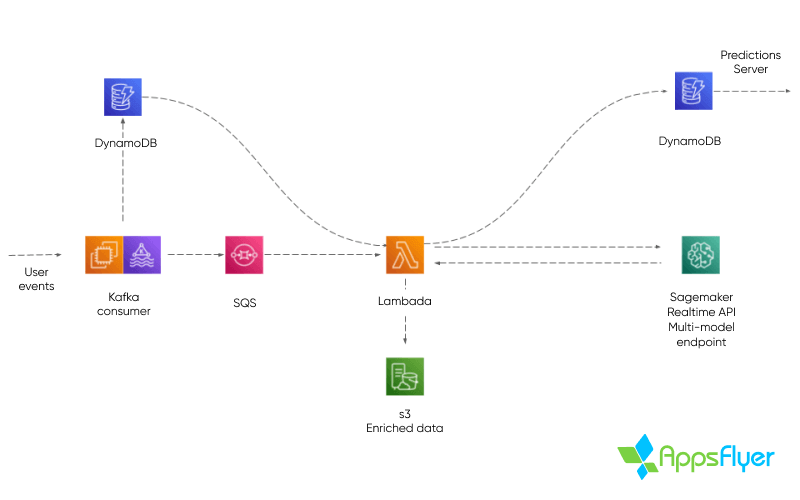
Decidimos construir nuestro sistema de producción utilizando Amazon Sagemaker para inferencias en tiempo real. Sagemaker ofrece una solución de punto de conexión multitenencia y en tiempo real, que se puede personalizar para trabajar con diversos marcos de ML y admite algoritmos personalizados como el que desarrollamos.
También decidimos utilizar los servicios administrados de AWS, como Lambda, SQS y DynamoDB, para acelerar el proceso de desarrollo, mientras seguíamos obteniendo la escalabilidad y estabilidad que nuestro producto requería.
El sistema de producción ingiere eventos en tiempo real de los SDK del cliente, que llegan a través de temas de Kafka. Los datos de eventos y los metadatos de usuario se almacenan en las tablas de DynamoDB y se realiza un proceso de decisión por evento consumido.
Si se produce una inferencia después del evento actual, cuando se decide una inferencia, los metadatos del usuario “predichos” se envían a una función Lambda a través de SQS. A continuación, los datos del evento se cargan dentro de la función Lambda, transformados para ML y se envían a Sagemaker para su inferencia. Una vez recibido un resultado, se almacena en otra tabla de DynamoDB.
Este proceso genera puntuaciones de usuario que el SDK del cliente puede solicitar como valores de conversión de SKAdNetwork en cualquier momento, y se actualizan con frecuencia a lo largo del tiempo para maximizar la precisión de las predicciones.
Capacitación de modelos
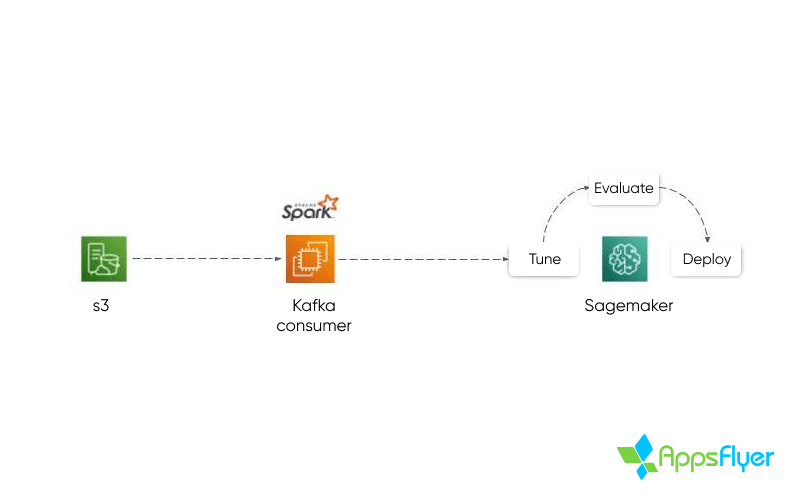
Antes del onboarding de una nueva aplicación para la predicción, se requiere un periodo de capacitación necesario en el que se analizan y revisan todos los datos históricos propios de la aplicación mediante AWS Sagemaker. El proceso está destinado a identificar y modelar diferentes tipos de correlaciones, y se reiterará hasta alcanzar niveles satisfactorios de precisión del modelo.
La precisión del modelo se revisa utilizando múltiples estadísticas; MAE: el error absoluto medio del modelo (por categoría), RMSE: el error cuadrado medio raíz, y Kappa de Cohen para garantizar la validez e integridad del modelo.
Se realizarán los ajustes necesarios en el modelo introduciendo puntos de datos adicionales, modificando las ponderaciones relativas de eventos específicos y las etiquetas. Todo esto es en un intento de perfeccionar el modelo antes del lanzamiento.
Una vez que se completa el onboarding y se lanzan las campañas, los nuevos usuarios comenzarán a descargar e interactuar con la aplicación, generando nuevos datos a través del SDK de AppsFlyer. Predict calcula la puntuación de beneficios de un usuario en función de los 3 pilares de engagement, retención y monetización. Esta puntuación de beneficios se calculará en comparación con el costo de la campaña para proporcionar una puntuación completa y procesable.
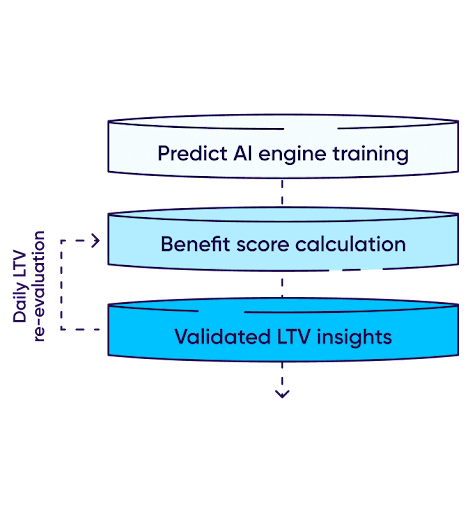
El proceso de reevaluación de la puntuación se repite constantemente durante la ventana de medición del usuario (generalmente 24 horas) con el objetivo de producir una puntuación predictiva precisa.
Al igual que con otros productos de AppsFlyer, la infraestructura de AWS nos permite realizar esta operación compleja a escala, y los productos como AWS Sagemaker nos permiten realizarla en una forma multitenencia que nos permite crear y aplicar modelos predictivos únicos en diferentes aplicaciones y desarrolladores de manera aislada.


